 HomeIndexTODOЗадачи
HomeIndexTODOЗадачи GitHub
</>
GitHub
</>
Основы программирования
В данном разделе рассматриваются вопросы, которые необходимо решить перед началом программирования. К ним относятся: устройство вычислительных машин, способы представления данных, языки программирования.
Описывается общая схема и принцип работы некоего вычислительного устройства, которое способно выполнять функции персонального компьютера (ПК), смартфона или другого подобного устройства.
Данное устройство выполняет операции с числами. Операции с другими типами данных (текст, изображение, звук) могут быть реализованы через операции с числами и в данном документе они не рассматриваются. Числа рассматриваются как некие значения, представление чисел не рассматривается.
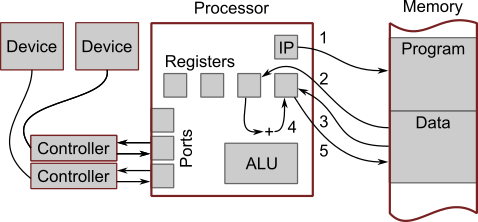
Processor — комплексное устройство, выполняющее операции с числами:
+, -, *, / и некоторые другие);>, <, == и некоторые другие);IP — instruction pointer, указатель инструкций. Указывает на инструкцию, которая будет выполнена после текущей инструкции. После отправки инструкции на выполнение IP автоматически переключается на следующую инструкцию. Возможно программное изменение указателя.
Registers — регистры, ячейки памяти внутри процессора. В регистры помещаются значения, с которыми в данные момент выполняются операции. Операции с числами могут быть выполнены только в регистрах.
ALU — arithmetic logic unit, арифметико-логическое устройство. Ответственно за выполнение арифметических и логических операций (см. выше).
Port — канал взаимодействия с внешними устройствами. Запись в порт это отправление числа внешнему устройству, чтение из порта получение числа с внешнего устройства.
Controller — средство взаимодействия с конкретным устройством. Его можно рассматривать как специфический компьютер. Различные типы устройств требуют свои типы контроллеров (контроллер мыши, контроллер клавиатуры и т.п.).
Контроллер преобразует сигналы из порта в определенное поведение внешнего устройства. Например: отправка последовательности чисел к контроллеру монитора вызывает изменение изображения на экране.
Так же контроллер преобразует воздействие на внешнее устройство в получение процессором чисел из порта. Например: при нажатии клавиши на клавиатуре или движении мыши процессор считывает из соответствующего порта последовательность чисел.
Device — внешние устройства например, мышь, клавиатура, монитор. Жесткий диск, даже если находится внутри корпуса компьютера, с точки зрения данной архитектуры является внешним устройством.
1 — Процессор считывает инструкцию по адресу, который находится в IP. IP автоматически переключается на следующую инструкцию.
2 — Процессор считывает число из памяти в регистр. Предположим, что инструкция предписывает процессору считать из некой ячейки памяти число 2 и поместить его в некий регистр.
3 — Согласно следующей инструкции процессор считывает из памяти другое число, например 3.
4 — Следующая инструкция прибавляет к числу в одном регистре число из другого регистра.
5 — Следующая инструкция записывает в память по некоему адресу число из некоего регистра.
Инструкции выполняются в том порядке, в котором они расположены в памяти. Такой порядок называется последовательным. Это происходит потому что IP каждый раз переключается на следующую инструкцию. Существуют инструкции, которые явно записывают адрес следующей команды в IP, они называются инструкциями перехода и могут быть инструкциями:
Таким образом происходит ветвление программы.
Если в IP записывается адрес предыдущей инструкции, то таким образом можно получить циклическое выполнение.
Современные вычислительные устройства изготавливаются на основе полупроводниковых компонентов. Первые электрические вычислительные машины строились на основе реле, а позже на основе электронных ламп. Самые первые счетные машины имели механический принцип действия.
Информацию можно рассматривать как знание. Лингвистически выражения "я знаю" и "я обладаю информацией" эквивалентны. Однако в технических науках используют более объективное понятие, данные, которые представляются как фиксация процессов реального мира на материальном носителе. Такими носителями являются например, бумага и чернила, воздух (для передачи звука), электромагнитные колебания (для передачи радиоволн и света). Таким образом данные являются объективными, т.е. они не зависят от особенностей воспринимающего субъекта.
Информация, при этом, является субъективной категорией и представляет собой результат восприятия данных конкретным субъектом. Типичным примером является восприятие текста человеком, который понимает язык этого текста и человеком, который его не понимает. Текст это данные, он один и тот же, т.е. он объективен. Информация при этом будет получена этими людьми разная: первый человек поймет смысл текста, второй — получит информацию, например, о размере текста или может быть даже догадается, какой это язык, но смысл текста не поймет.
Дальнейшие рассуждения будут касаться данных.
Применительно к данным выполняются операции: создание, фиксация, хранение, передача. При выполнении операций важным является вопрос измерения данных, например для определения параметров устройств хранения, а также скоростных характеристик. Логичным подходом в данном вопросе является определение минимально возможного количества данных. Если таковое будет найдено, то его можно принять за единицу измерения. Для этого рассмотрим информативность объекта способного принимать N возможных состояний. Такой объект имеет одно из N состояний, поэтому будем считать, что чем больше N, тем информативнее объект. Минимальное количество состояний при котором объект является информативным равно 2, потому что объект только с одним состоянием является неизменным и поэтому данных не несет. Договорились что объект с двумя возможными состояниями несет количество данных размером 1 бит. Если обозначить состояния 0 и 1, то такой объект можно назвать разрядом в двоичной системе счисления. Два таких разряда несут количество данных 2 бита и представляют 4 возможных состояния (значения). 3 бита позволяют представить 8 значений и т.д.
Такой способ представления данных реализован в современных вычислительных устройствах. 1 бит является минимальным значимым элементом, однако минимальной единицей адресации как правило является блок из 8 бит, который называется 1 байтом. 1 байтом можно представить 28 = 256 состояний, например, число от 0 до 255. Для измерения бОльших объемов данных используются кратные единицы:
Для примера если кодировать текст 1-им байтом на символ, то стандартная печатная страница, которая содержит 2000 символов будет занимать объем данных примерно 2 килобайта.
Рассмотренное в данном документе вычислительное устройство работает только с числами, поэтому чтобы обрабатывать другие типы данных, их необходимо представить в виде чисел.
Используемые нами арабские десятичные числа описываются позиционной системой счисления с основанием 10. Существуют другие системы счисления (например римская), которую мы не будем рассматривать в данном разделе.
В позиционной системе счисления с основанием N разряды начиная с младшего имеют следующий вес:
| Разряд | N-ичная СЧ | Десятичная СЧ | Пятеричная СЧ | Троичная СЧ | Двоичная СЧ |
|---|---|---|---|---|---|
| 1 | N0 | единицы | единицы | единицы | единицы |
| 2 | N1 | десятки | пятерки | тройки | двойки |
| 3 | N2 | сотни | двадцатьпятки | девятки | четверки |
| ... | и т.д. |
Покажем некоторые примеры чисел в различных системах счисления:
| Система счисления | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Десятичная | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| Пятеричная | 0 | 1 | 2 | 3 | 4 | 10 | 11 | 12 | 13 | 14 | 20 | 21 | 22 | 23 | 24 |
| Троичная | 0 | 1 | 2 | 10 | 11 | 12 | 20 | 21 | 22 | 100 | 101 | 102 | 110 | 111 | 112 |
| Двоичная | 0 | 1 | 10 | 11 | 100 | 101 | 110 | 111 | 1000 | 1001 | 1010 | 1011 | 1100 | 1101 | 1110 |
| Шестнадцатеричная | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E |
В шестнадцатеричной системе счисления каждый разряд выражает значение от 0 до 1510 поскольку имеются символы (цифры) от 0 до 9, то договорились для оставшихся значений использовать латинские буквы от A до F. Рассмотрим типичные шестнадцатеричные числа:
| 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | ... | 31 | 32 | ... | 64 | ... | 128 | ... | 160 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | C | D | E | F | 10 | 11 | 12 | ... | 1F | 20 | ... | 40 | ... | 80 | ... | A0 |
Система счисления обозначается нижним индексом, например:
1110 = 215 = 1023 = 10112
Обычно числа в СЧ отличной от 10-ной читаются поразрядно, например: 125 читается как "один два", а не "двенадцать".
Для перевода в десятичную систему счисления используют степени основания системы счисления:
1023 = 1 * 9 + 0 * 3 + 2 * 1 = 1110
11012 = 1 * 8 + 1 * 4 + 0 * 2 + 1 * 1 = 1310
Для перевода из десятичной системы счисления используют последовательное деление с остатком:
10 / 2 = 5, ост. 0
5 / 2 = 2, ост. 1
2 / 2 = 1, ост. 0
1 / 2 = 0, ост. 1
Остатки записываются в обратном порядке: 1010 = 10102.
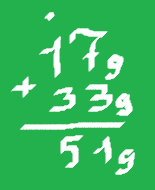
Числа в других системах счисления можно складывать в столбик так же как и десятичные числа. В нашем примере, 179 + 339 = 519, при сложении разрядов единиц одна девятка переносится в следующий разряд, следовательно в результат пишется единица, а не ноль, как это было бы в десятичной системе счисления.
Note
Также смотри эту задачу, которая демонстрирует работу с системами счисления.
При кодировании текста всем используемым символам назначается определенное число или код. Таблица соответствия символов и кодов называется кодировкой. За всю историю развития вычислительной техники было разработано большое количество кодировок, среди них можно выделить:
однобайтные, т.е. каждый символ кодируется числом от 0 до 255. Понятно что таким способом нельзя закодировать символы всех существующих алфавитов, поэтому используются так называемые кодовые страницы. Кодовые страницы это кодировка для определенного языка. В каждой кодовой странице коды от 0 до 127 совпадают и содержат английский алфавит, цифры, знаки препинания и общие специальные символы. Вторая часть таблицы, с кодами от 128 до 255 заполнена символами конкретного алфавита/языка. При этом все равно есть проблема с азиатскими языками.
многобайтные, т.е. на кодирование одного символа может выделяться более одного байта. Наиболее
распространенной можно назвать кодировку UTF-8.
В этой кодировке рассмотренные выше символы с кодами
от 0 до 127 кодируются так же одним байтом. Остальные символы могут иметь размер 2, 3, 4 и,
возможно, более байтов.
Рассмотренные выше способы кодирования чисел и текста можно обозначить термином формат. Формат является соглашением о представлении данных. Участники информационного процесса должны использовать согласованные форматы для успешного обмена данными в рамках информационного взаимодействия.
Текст является универсальным форматом представления данных. Из представленного выше описания можно сделать вывод, что формат кодирования текста может быть основан на формате кодирования чисел. То есть, символы текста кодируются (представляются) числами.
Текст может быть использован для представления данных более сложной структуры. Рассмотрим это на примере платежной ведомости:
Иванова 765.23
Петров 3452.15
Сидоров 645.65
...В данной ведомости каждый платеж представлен отдельной строкой, в каждой строке через последовательность пробельных символов представлены получатель и сумма выплаты.
Данный формат являются специализированным, т.е. предназначенным для использования ограниченным кругом пользователей и программ. Базовым форматом для данного формата является текстовый. Данный формат является текстовым, однако он накладывает дополнительные ограничения, т.е. каждая каждая платежная ведомость является текстом, но не каждый текст является платежной ведомостью.
Характерной особенностью формата данной платежной ведомости является наличие структуры, т.е. мы можем выделить упорядоченный список выплат, а в каждой выплате получателя и сумму. Базовый текстовый формат такой структуры не представляет.
Существуют универсальные форматы представления структурированных данных, такие как XML и JSON. Формат JSON является более простым, поэтому рассмотрим только его на следующем примере:
{
"payouts": [
{"name": "Иванова", "amount": 765.23},
{"name": "Петров", "amount": 3452.15},
{"name": "Сидоров", "amount": 645.65}
],
"payments": [
{"name": "Белов", "amount": 986.63},
{"name": "Чернов", "amount": 8762.85},
{"name": "Краснов", "amount": 123.60}
]
}Формат JSON позволяет представлять сущности трех типов:
В нашем примере представлена структура включающая платежную ведомость (кому сколько платить) и ведомость платежей (от кого сколько принять). Данная структура, очевидно, является специализированной, поскольку предназначена для использования в конкретной предметной области. В тоже время формат JSON является универсальным, поскольку манипулирует понятиями значения, списка, словаря, которые используются в различных предметных областях.
На данный момент мы можем выявить следующую иерархию форматов:
Существует возможность определить схему JSON,
которая определяет допустимое содержание документа. В этой схеме определяются: корневой элемент
(массив или объект), для массива — структура элементов, для объекта — ограничения на ключи и
структура значений. Поддерживаются так же и другие ограничения.
В нашем примере схема может выглядеть следующим образом:
"payouts" и "payments";"name" строкового типа и поле "amount" числового типа.Поскольку формат JSON является универсальным, то существуют библиотеки для разных языков программирования, позволяющие преобразовывать текстовое представление в структуры характерных для этих языков.
Схема JSON позволяет автоматически проверить (валидировать) документ JSON на соответствие этой схеме (разумеется, требуются специальные библиотеки для этого).
При кодировании изображений используются два основных подхода:

Изображения представляются как прямоугольная матрица, каждая ячейка которой называется пикселем и представляет цвет точки. Отдельно может кодироваться размер печатного оттиска и другие параметры.
Размер одного пикселя определяется параметрами выводного устройства (монитора, принтера).
Количество пикселей на единицу длины называется разрешением и может относится как к выводному
устройство, так и к изображению. Для выводного устройства разрешение измеряется в dpi (от англ.
dots per inch — точки на дюйм). Типичное разрешение монитора составляет 72 или 96 dpi. Типичное
разрешение принтера 300 dpi для цветных и серых изображений или 800 dpi для черно-белых.
Второй важной характеристикой растрового изображения является глубина цвета, т.е. диапазон чисел которыми кодируется цвет каждой точки. Глубина цвета определяет количество различных цветов, которое может иметь точка. Минимальной глубиной цвета является два. Такие изображения называются монохромными, например черно-белые и т.д. Для кодирования одной точки такого изображения достаточно 1 бита, т.е. 1 байтом можно закодировать 8 точек.
Изображения в оттенках серого кодируют каждую точку 1 байтом: 0 — черный, 255 — белый. Разумеется все оттенки серого закодированы быть не могут, однако считается что человеческий глаз не различает разницу между соседними оттенками.
Цветные изображения раскладываются на три составляющих (канала): красный (R), зеленый (G), синий (B). Каждый канал использует 1 байт для кодирования каждой точки, таким образом каждая точка цветного изображения кодируется 3 байтами. Данная модель цветности является распространенной, но не единственной.
Достоинство растровых изображений:
Недостатки:

Изображение представляется в виде набора фигур (примитивов), таких как линия, прямоугольник, эллипс. Каждая фигура имеет определенные параметры, такие как цвет, толщина линии, цвет заливки, координаты опорных точек (например, координаты концов отрезка). Эти параметры, естественно кодируются числами. Цвет может кодироваться также, как и в растровом изображении.
Понятие разрешения для векторных изображений не является актуальным, однако возможно определить точность задания координат и размеров.
Достоинство векторных изображений:
Недостатки:
Рассматриваются общие характеристики различных типов языков программирования.
Синтаксис языка состоит из элементов алфавита данного языка, ключевых слов, пунктуации, а также правил написания корректных программных текстов.
Семантика языка определяет смысл синтаксических конструкций, т.е. набор действий, которые будут выполнены в соответствии с написанной программой.
Разнообразие языков программирования можно посмотреть здесь.
Вычислительное устройство, описанное в главе Архитектура ПК выполняет инструкции находящиеся в памяти и представляющие собой набор чисел. Механизм исполнения инструкции реализован конструктивно, посредством, например: электронных схем, определенным образом соединенных электрических реле, собранных определенным образом механических элементов.
Набор всех возможных инструкций, описание их действий и способов их указания представляет собой язык программирования.
Машинный язык состоит из инструкций, которые выполняются непосредственно процессором, т.е. программа на этом языке загружается в оперативную память (как есть), в IP записывается адрес первой инструкции этой программы и программа начинает выполняться. Машинный язык является языком низкого уровня (ЯНУ).
Преимущество ЯНУ. ЯНУ позволяют писать более эффективные программы поскольку представляет доступ ко всем возможностям процессора.
Недостатки ЯНУ. Писать программы на ЯНУ трудоемко, требует высокой квалификации.
Для упрощения программирования на ЯНУ был создан язык в котором цифровые коды программ представлены буква-сочетаниями похожими на слова естественного языка, в основном английского языка. Этот язык назвали языком ассемблера.
Такая программа не может быть выполнена непосредственно процессором. Перед выполнением она должна быть преобразована в программу на машинном языке. Для этого используется программа, которая часто называется ассемблер.
Язык ассемблера является ЯНУ, потому что его инструкции однозначно переводятся в инструкции машинного языка.
Языки программирования высокого уровня (ЯВУ) были созданы для упрощения и ускорения процесса разработки программ. Синтаксис этих языков включает более понятные человеку категории и действия, например:
Преимущество ЯВУ. Писать программы быстрее, легче.
Недостатки ЯВУ. Как правило нет доступа ко всем возможностям процессора и программы работают медленнее.
Для исполнения программ на ЯВУ, эти программы должны быть переведены (транслированы) в машинные инструкции. Существует два способа это сделать.
Компиляторы переводят всю программу на ЯВУ в программу на машинном языке. Полученная программа может быть исполнена.
Преимущество компиляции. Полученная программа работает быстрее.
Недостатки компиляции. Любое изменение программы требует перекомпиляции.
Каждая инструкция на ЯВУ последовательно переводится в машинные инструкции и тут же исполняется.
Преимущество интерпретации. Измененная программа может быть сразу выполнена.
Недостатки интерпретации. Программа, очевидно, работает медленнее, т.к. каждый раз требуется перевод в машинные инструкции. Некоторые "умные" интерпретаторы могут запоминать транслированные фрагменты программ, что в какой-то степени повышает производительность.
Программы, которые мы обсуждали до сих пор, пишутся под конкретные аппаратные платформы и операционные системы(ОС). Создание версий программы для других платформ и ОС — процесс трудоемкий. Для облегчения этого процесса были созданы языки программирования (ЯП), которые транслируются не в машинный код, а в программу для некоей виртуальной машины (ВМ). Такая программа часто называется байт-кодом. ВМ — это транслятор. Байт-код может выполняться на той платформе, для которой написан соответствующей ВМ. Компилятор компилирует из ЯВУ (Python, Java) в байт-код, и он выполняется на трансляторе(ВМ) переводя в машинный код и выполняется.
Также смотри в Википедии: Java Virtual Machine

